Bilibili 開源的 IndexTTS2:當 AI 不只會說話,還會「帶感情」說話
傳統語音克隆無法分離音色與情感、難以控制時長、強調情緒時發音不清。Bilibili 開源的 IndexTTS2 只需 3-15 秒音訊樣本,實現情感與音色解耦控制、精確時長控制,在 benchmark 測試中超越 CosyVoice2、F5-TTS 等主流系統。

你可能遇過這些語音克隆的痛點
如果你用過語音克隆工具,應該遇過這些狀況:
「我只想要他的聲音,不想要他的情緒」 — 你找了一段聲音樣本來克隆,結果發現無論生成什麼內容,都帶著原始樣本的語氣。想要同一個聲音表達不同情緒?要麼重新找樣本訓練,要麼就得接受品質大幅下降。
「為什麼生成的長度每次都不一樣?」 — 你在做影片配音,畫面長度是 15 秒,但 TTS 系統生成的語音可能是 13 秒,也可能是 18 秒。你只能一直重跑,祈禱某次剛好符合需求。
「情緒越強,發音越糟」 — 當你想要生成「憤怒」或「興奮」的語音時,系統確實會加強情緒表現,但代價是發音變得不清晰,甚至出現斷句錯誤或雜訊。
「中文多音字總是唸錯」 — 「重要」的「重」該唸 chóng 還是 zhòng?「行」該唸 xíng 還是 háng?傳統 TTS 系統在中文多音字上的錯誤率一直居高不下。
「我不是語音工程師,為什麼要調一堆參數?」 — 面對一堆專業參數(pitch、tempo、emotion vector),你根本不知道該怎麼調整才能得到想要的效果。
這些痛點不是你的問題,而是技術架構的限制。傳統語音克隆系統把「音色」和「情感」綁在一起訓練,自迴歸模型難以精確控制時長,強情緒表達會犧牲清晰度,而複雜的參數設計則把大部分非專業使用者拒之門外。
第一次試用 IndexTTS2 的時候,我給它餵了 10 秒我自己的聲音,然後讓它用「興奮」的語氣唸一段技術文件。結果出來的聲音讓我愣了一下——那確實是我的音色,但語氣卻像是我在台上分享成功案例時的狀態。更驚人的是,整段語音的節奏和停頓,完全符合我設定的時長要求。
這些傳統痛點,IndexTTS2 一次解決了。
核心突破:情感與音色的解耦控制
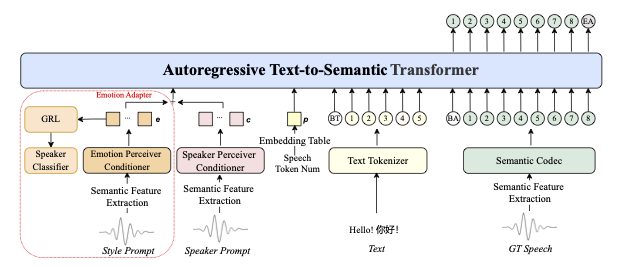
IndexTTS2 最大的技術突破,是從架構層面實現了情感與說話人特徵的解耦控制。這代表什麼?
簡單說,你可以:
- 用音色樣本 A + 情感樣本 B = 生成「A 的聲音 + B 的情緒」
- 同一個聲音,透過不同的情感描述,產出完全不同的表達方式
- 用自然語言描述情緒(「用興奮的語氣說」),而不需要調整複雜的參數
這在技術上很難。大部分 TTS 系統把音色和情感混在一起學習,要分開控制就像要把攪拌好的蛋液再分離出蛋白和蛋黃一樣困難。根據 arXiv 論文 顯示,IndexTTS2 在情感表達的主觀評測中,聽眾一致性地給予比 CosyVoice2 或 F5-TTS 更高的評分。
時長控制:被低估但致命重要的能力
另一個突破是精確時長控制。這聽起來像是個小功能,但對實際應用來說卻是致命痛點。
想像你在做影片配音,畫面長度是 15 秒,你需要生成的語音必須剛好填滿這 15 秒,不能多也不能少。傳統的自迴歸 TTS 模型雖然語音自然,但逐 token 生成的機制讓時長控制變得非常困難。你可能跑十次才能碰巧得到一個長度剛好的結果。
IndexTTS2 是第一個在自迴歸架構下實現精確時長控制的零樣本 TTS 系統。在 test-zh 數據集上,IndexTTS2 在時長控制準確度上超越 F5-TTS 達 0.5 個百分點,超越 MaskGCT 達 2 個百分點。
更重要的是,這個控制不會犧牲語音的自然度。你可以指定「這段話要在 12 秒內說完」,系統會自動調整語速和停頓,而不是機械式地加快或放慢播放速度。
只需 3-15 秒樣本,不用訓練模型
傳統語音克隆有個門檻:你需要準備大量訓練數據,然後花時間訓練模型。雖然現代系統已經進步到 只需 1-2 分鐘音訊,但 IndexTTS2 更進一步——只需 3-15 秒的音訊樣本,無需訓練,立即可用。
這是「零樣本」(Zero-Shot)的真正意義:
- 不需要為每個新聲音重新訓練模型
- 不需要準備大量訓練數據
- 不需要等待數小時的訓練時間
- 隨時換聲音,隨時可用
這讓語音克隆從「專業工具」變成「即用即走的服務」。
與競品的真實對比:不只是跑分遊戲
我特別去看了 VoiceClone Benchmark 的對比測試,這個測試對比了 IndexTTS、Fish-Speech-1.5、SparkTTS、CosyVoice2 和 F5-TTS 五個系統,使用相同的參考音訊和合成文本來評估聲音相似度、自然度和表現力。
結果很有意思:
情感表達的清晰度:其他系統在強烈情緒表達時容易出現發音不清或語義不流暢的問題,IndexTTS2 則能在保持高情緒表現力的同時,維持發音清晰度。這解決了我前面提到的「情緒越強,發音越糟」的痛點。
穩定性:CosyVoice2 在完整片段合成時出現 OOM(記憶體溢出)錯誤,需要手動分割成 5 個部分才能完成,而 IndexTTS2 可以一次性處理完整片段。
多音字準確度:在中文場景下,IndexTTS2 在多音字發音準確性上明顯優於其他系統,解決了「重要」該唸 chóng 還是 zhòng 的老問題。
真實使用場景:誰會需要這個?
看完技術細節,我反而想聊聊「誰會用」的問題。因為很多開源專案的問題不是技術不夠強,而是找不到真正的使用場景。
影音創作者的救星:你在做影片配音,需要同一個角色在不同場景表達不同情緒。傳統方法要麼找配音員重錄(成本高、時間長),要麼接受機械的情緒轉換(品質差)。IndexTTS2 讓你用一次錄音,產出多種情緒表達,且能精確對齊畫面時長。
多語言內容本地化:假設你是 YouTuber,想把影片翻譯成多國語言。傳統做法是找各國配音員,但這樣會失去你原本的聲音特徵。IndexTTS2 可以用你的聲音特徵,合成不同語言或不同情緒的版本。
輔助科技的新可能:為語音障礙人士提供個性化的語音合成服務。傳統方法需要大量訓練數據,但很多患者沒有足夠的清晰語音樣本。IndexTTS2 只需 3-15 秒,大幅降低了門檻。
遊戲開發的效率提升:遊戲角色通常需要大量對話語音,且同一句話可能在不同情境下需要不同情緒。傳統做法是錄製多個版本,IndexTTS2 讓你錄一次,生成多種情緒變化。
開源的價值:不只是免費使用
IndexTTS2 採用 MIT License 完全開源,包含預訓練模型權重(訓練自 55,000 小時多語言語料)、推理程式碼和 Web 介面。這對產業來說意義重大。
過去,高品質的情感 TTS 系統幾乎都是商業閉源的。開發者要麼付費使用 API(按使用量計費,成本不可控),要麼自己從零訓練模型(需要大量算力和專業知識,成本極高)。IndexTTS2 的開源讓中小團隊和個人開發者也能使用工業級的 TTS 技術,這會加速相關應用的創新。
但我更看重的是技術透明度。開源意味著研究者可以深入理解架構設計、訓練策略和優化技巧,這對整個領域的進步比單一產品的成功更有價值。
也要看清限制
但同時也要認清限制:這仍然是個需要一定技術門檻的工具。雖然提供了 Web 介面,但要達到最佳效果,你還是需要理解:
- 參考音訊的品質要求(清晰、無雜訊、無背景音)
- 情感描述的精確度(自然語言描述雖然方便,但仍需精準表達)
- 不同語言的支援程度(中英文效果最好,其他語言可能有限制)
而且,跟所有 AI 語音技術一樣,倫理與法律風險 不容忽視。語音克隆可能被用於詐騙、假冒身份等惡意用途,使用者需要負起責任。
結語:語音合成的下一步
IndexTTS2 讓我想起 Stable Diffusion 剛開源時的狀態——技術上已經達到可用水準,開源釋放了巨大的創新能量,但距離「人人可用」還有一段路要走。
語音合成的終極目標,不是複製聲音,而是表達意圖。當 AI 能理解你要表達的情緒、語氣、節奏,並自動選擇最合適的方式呈現時,我們才算真正解決了「讓機器說話」這個問題。
IndexTTS2 在情感解耦、時長控制、零樣本克隆上的突破,讓我們離這個目標又近了一步。更重要的是,它用開源的方式,邀請整個社群一起往前走。
參考資料