2 條知識圖譜路線 + 4 個選型問題:Graphify 與 Andrej Karpathy LLM Wiki,我會怎麼選
如果你最近也在研究怎麼把文件、論文、筆記與程式碼變成可累積的知識庫,Graphify 與 Andrej Karpathy 的 LLM Wiki 其實代表兩條不同路線:一條偏機器可遍歷的 graph,一條偏人類可閱讀的 wiki。這篇文章我會拆解兩者的核心差異、共同點,以及什麼情境下該單獨用、什麼情境下該一起用。
2 條知識圖譜路線 + 4 個選型問題:Graphify 與 Andrej Karpathy LLM Wiki,我會怎麼選
最近我在看兩種很有代表性的知識管理做法。一種是你真的可以直接安裝的 Graphify,另一種則是 Andrej Karpathy 在 2026 年 4 月 4 日公開的 llm-wiki.md。表面上,它們都在處理「把一堆資料變成可用知識」這件事,但我認為它們其實不是同一類產品。
先講我的結論。Graphify 比較像 graph first 的做法,目標是把原始資料抽成可遍歷、可查詢、可壓縮 token 成本的結構。Karpathy 的 LLM Wiki 則是 wiki first 的做法,目標是讓 LLM 持續維護一套人能讀、能連、能逐步累積觀點的知識庫。兩者都不是傳統那種「丟進去,問問題時再臨時撈 chunk」的 RAG 思路,但它們優化的重點完全不同。
先把名字講清楚
如果你是從安裝開始接觸 Graphify,第一個容易卡住的點其實是命名。根據官方說明,截至 2026 年 4 月 8 日,PyPI 套件名稱還是 graphifyy,但 CLI 跟 skill 指令都叫 graphify。也就是說,你會用 pip install graphifyy,但實際操作是跑 graphify install 或在 Codex 裡呼叫 $graphify。
這件事很小,但也剛好透露出 Graphify 的定位。它不是單純的 Python 函式庫,而是面向 Claude Code、Codex 這類 agent 環境的知識圖譜工作流。它想解決的不是「你能不能存資料」,而是「agent 之後能不能不要每次都從 raw files 重新讀起」。
Graphify 在解什麼問題
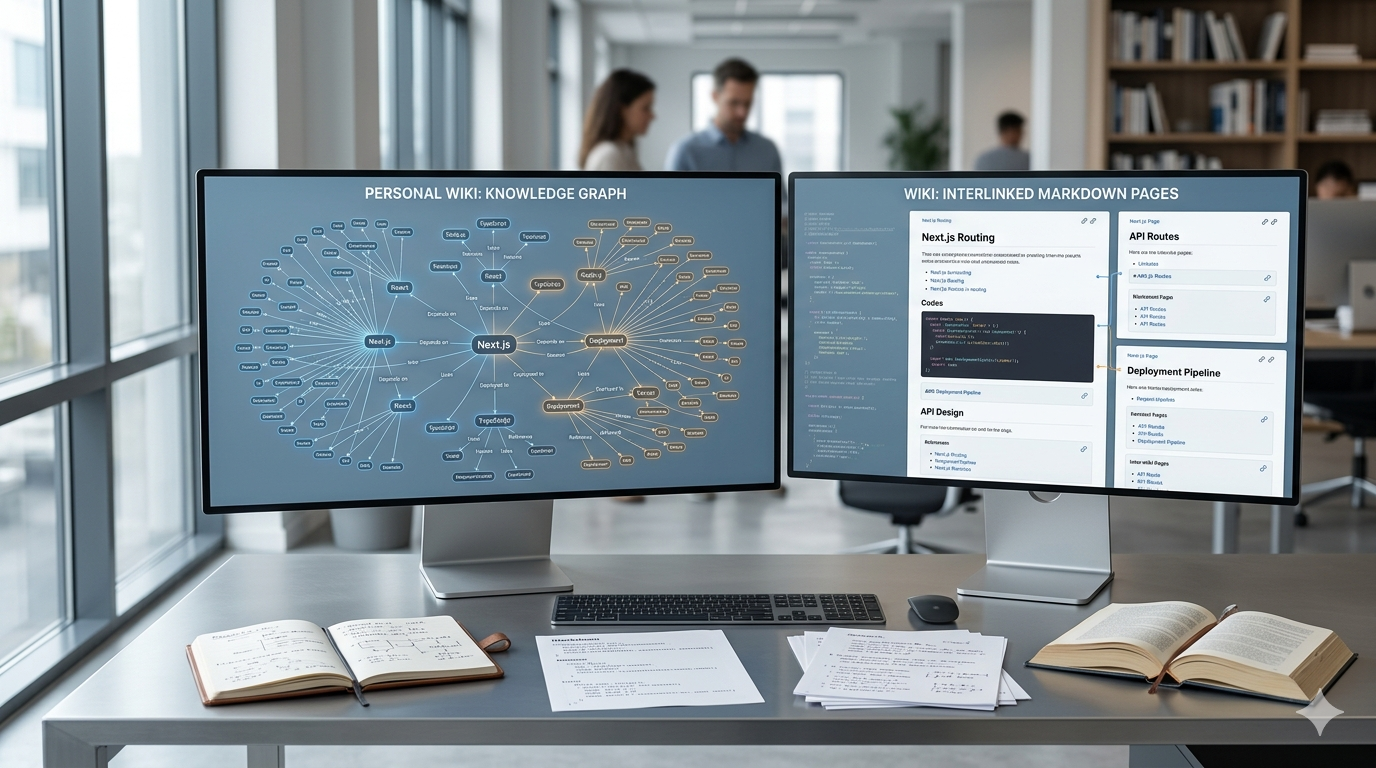
Graphify 的核心很明確,就是把資料夾裡的程式碼、文件、論文、圖片,整理成一個持久化 knowledge graph。官方描述它是兩段式流程:先做 deterministic AST 擷取,再做語意層的關係抽取,最後輸出成 graph.json、GRAPH_REPORT.md、互動式 graph.html,也可以額外生成 wiki。
我認為這條路線最有價值的地方有三個。
第一,它很重視「結構先於問答」。你不是把檔案丟給模型,等下次問問題再看運氣撈到哪些 chunk;你是先把關係建好,之後再沿著節點、社群、路徑去查。
第二,它很重視「可區分事實與推論」。官方把關係分成 EXTRACTED、INFERRED、AMBIGUOUS,這件事很重要。因為知識圖譜一旦看起來太漂亮,人就很容易忘記裡面有些邊其實只是合理猜測,不是原文明講。
第三,它很重視「讓 agent 先看地圖再看原文」。這點其實很符合實戰。大型 repo、研究筆記庫、混合型資料夾,最浪費 token 的往往不是回答本身,而是每次都要重新定向。Graphify 想做的,就是先給 agent 一張地圖。
Karpathy 的 LLM Wiki 在解什麼問題
Karpathy 的 LLM Wiki 不是一個套件,也不是一個現成產品。它更像是一份方法論,核心觀念是:不要讓 LLM 每次問答都從 raw documents 重新發現知識,而是讓它持續維護一套 interlinked markdown wiki,把新來源整合進既有頁面、修正舊結論、標記衝突、補上交叉連結。
我很喜歡這個想法,因為它抓到一個真正的痛點。多數人不是沒有資料,而是沒有一個會自我整理、會持續更新、會把零散閱讀變成累積資產的中間層。Karpathy 說得很直接,wiki 才是那個 persistent artifact。知識不是每次 query 時重建,而是先被 compile 成可閱讀、可維護的頁面。
這條路線的強項,不在圖譜有多漂亮,而在知識會不會越用越厚。當你研究一個主題很多週、很多月之後,你需要的往往不是更快找到一段文字,而是更快看到:這件事目前的主線論點是什麼,哪些觀點互相矛盾,哪些人物、概念、事件已經被連在一起。這正是 wiki 比 graph 更適合承載的地方。
兩者真正的差異,不是資料結構,而是主要讀者
如果只看技術名詞,Graphify 跟 LLM Wiki 都在做知識整理。但我認為真正的分水嶺,其實是誰是主要讀者。
如果你的主要讀者是 agent,Graphify 更合理。因為它輸出的核心價值是可遍歷、可摘要、可用來引導後續檢索的結構。
如果你的主要讀者是人,Karpathy 的 LLM Wiki 更合理。因為它輸出的核心價值是頁面、敘事、連結、索引、log,以及逐步形成的觀點。
換句話說,Graphify 比較像幫 agent 建立「地圖」,LLM Wiki 比較像幫人建立「百科全書」。地圖跟百科全書都重要,但使用時機不同。
我會用哪 4 個問題來選
- 你的主要使用者是 agent,還是人?
- 你的資料來源是多模態混合,還是以文字筆記為主?
- 你想要的是可追蹤的關係,還是可閱讀的 synthesis?
- 你現在最大的成本,是重複檢索,還是重複整理?
如果你痛的是每次問答都要重新讀一堆原始資料,Graphify 解得更直接。若你痛的是知識總是散在聊天、筆記、檔案裡,卻沒有被沉澱成長期資產,那 LLM Wiki 的價值更高。
真正值得注意的是,它們其實可以一起用
我認為最有意思的地方,不是二選一,而是兩者其實正在往同一個方向靠攏。Karpathy 的 LLM Wiki 想把知識 compile 成可維護的 wiki;Graphify 則已經開始提供 wiki 類型輸出,等於是把 graph first 的結果再轉成 wiki first 的閱讀介面。
這代表什麼?代表知識圖譜跟 wiki,未必是競爭關係,更像上下層。
Graphify 可以幫你先把 heterogeneous corpus 變成可導航的結構,快速找到社群、核心節點、關鍵連結。接著,你再讓 LLM Wiki 風格的工作流去維護高價值頁面,把這些結構轉成真正可讀、可討論、可逐步演化的知識庫。前者偏萃取與導航,後者偏沉澱與累積。
我的結論
如果你現在只想選一條路,我會這樣建議。
你要的是 agent 能更快理解大型資料夾、混合資料、研究素材,先用 Graphify。
你要的是長期研究、主題學習、個人或團隊知識庫,先用 LLM Wiki。
但如果你問我哪個方向更接近未來,我的答案反而不是其中一個。我認為未來真正成熟的知識系統,會同時有 graph layer 和 wiki layer。因為只有 graph,容易變成模型很會走但人不愛讀;只有 wiki,則容易變成人能看懂但機器不夠好遍歷。真正強的系統,會同時照顧機器導航與人類理解。
所以這篇文章如果只能留下一个判斷,我會留這句:Graphify 不是 Karpathy LLM Wiki 的替代品,Karpathy LLM Wiki 也不是 Graphify 的簡化版。它們是在回答同一個大問題的不同子題,而最值得做的,往往不是站隊,而是把兩者接起來。